


ChatGPT, developed by OpenAI, is a state-of-the-art language model that leverages the power of the Transformer architecture to generate human-like text. The name "ChatGPT" stands for "Chat Generative Pre-trained Transformer," which succinctly captures its core functionality: generating coherent and contextually relevant text based on the input it receives. This model has been pre-trained on a diverse range of internet text, enabling it to understand and generate text in a way that mimics human conversation.
The underlying technology of ChatGPT is the Transformer architecture, introduced in the groundbreaking paper "Attention is All You Need" by Vaswani et al. in 2017. This architecture has revolutionized the field of natural language processing (NLP) by enabling models to handle long-range dependencies in text more effectively than previous models like RNNs (Recurrent Neural Networks) and LSTMs (Long Short-Term Memory networks).
Examples of ChatGPT in Action
To appreciate the capabilities of ChatGPT, let's explore a few examples of how it can be used in various scenarios:
-
Creative Writing:
- Prompt: "Write a small haiku about the importance of understanding AI."
- Response:
AI knowledge brings Prosperity for all to see Embrace its power - Alternate Response:
AI is power To grow, ignorance holds us back Learn, prosperity waits
-
Humorous Requests:
- Prompt: "Explain HTML to me like I'm a dog."
- Response:
Woof! HTML is like the bones of a website. It gives structure to the content, like how your bones give structure to your body. Woof woof!
-
Fictional News:
- Prompt: "Write a breaking news article about a leaf falling from a tree."
- Response:
In a shocking turn of events, a leaf has fallen from a tree in the local park. Witnesses report that the leaf, which was previously attached to a branch, detached itself and fell to the ground. Very dramatic.
-
Tech Commentary:
- Prompt: "Write a note about Elon Musk buying Twitter."
- Response:
In a surprising move, Elon Musk has announced his acquisition of Twitter. The tech mogul plans to implement several changes aimed at enhancing user experience and promoting free speech on the platform.
These examples illustrate the versatility of ChatGPT. Whether it's generating poetry, explaining technical concepts in a humorous way, creating fictional news stories, or providing commentary on current events, ChatGPT can handle a wide range of text-based tasks with impressive fluency and creativity.
In the next sections, we'll delve deeper into the mechanics of how ChatGPT works, exploring the neural network architecture that powers it and how you can build your own Transformer-based language model. Stay tuned!

The Basics of Language Models
Understanding Language Models
Language models are a fundamental component of natural language processing (NLP) systems. They are designed to understand and generate human language by predicting the next word or sequence of words in a given context. The primary goal of a language model is to capture the statistical properties of language, enabling it to generate coherent and contextually appropriate text.
At its core, a language model assigns probabilities to sequences of words. For example, given a sequence of words , the model predicts the probability of the next word . This can be mathematically represented as:
The higher the probability, the more likely the model believes that the word is the correct continuation of the sequence.
Language models can be categorized into different types based on their architecture and training methodology:
-
N-gram Models: These are the simplest form of language models that use fixed-length word sequences (n-grams) to predict the next word. For example, a bigram model uses pairs of words, while a trigram model uses triplets. However, n-gram models have limitations in capturing long-range dependencies due to their fixed context window.
-
Recurrent Neural Networks (RNNs): RNNs are a type of neural network designed to handle sequential data. They maintain a hidden state that captures information from previous time steps, allowing them to model longer dependencies. However, RNNs suffer from issues like vanishing gradients, which can hinder their ability to capture very long-range dependencies.
-
Long Short-Term Memory Networks (LSTMs): LSTMs are a variant of RNNs that address the vanishing gradient problem by introducing memory cells and gating mechanisms. This allows them to capture longer dependencies more effectively than standard RNNs.
-
Transformers: Introduced in the "Attention is All You Need" paper, Transformers have revolutionized NLP by using self-attention mechanisms to capture dependencies between words, regardless of their distance in the sequence. This allows Transformers to handle long-range dependencies more effectively than RNNs and LSTMs.
ChatGPT is built on the Transformer architecture, specifically using a variant called the Generative Pre-trained Transformer (GPT). The GPT model is pre-trained on a large corpus of text data to learn the statistical properties of language, and then fine-tuned on specific tasks to improve its performance.
Probabilistic Nature of ChatGPT
One of the key characteristics of ChatGPT is its probabilistic nature. Unlike deterministic systems that produce the same output for a given input every time, probabilistic models like ChatGPT can generate different outputs for the same input. This is because the model assigns probabilities to different possible continuations of a given text and samples from these probabilities to generate the next word or sequence of words.
To illustrate this, let's revisit the example of generating a haiku about the importance of understanding AI. When given the prompt:
Write a small haiku about the importance of understanding AI.ChatGPT might generate:
AI knowledge brings
Prosperity for all to see
Embrace its powerHowever, if we run the same prompt again, it might generate a slightly different haiku:
AI is power
To grow, ignorance holds us back
Learn, prosperity waitsBoth haikus are valid and coherent, but they differ in their wording and structure. This variability is a direct result of the probabilistic nature of the model. For any given prompt, ChatGPT can produce multiple plausible responses, each with its own probability.
This probabilistic behavior is achieved through the use of softmax functions in the model's architecture. The softmax function converts the raw output scores (logits) of the model into probabilities, which are then used to sample the next word in the sequence. The sampling process introduces randomness, allowing the model to generate diverse and creative outputs.
The probabilistic nature of ChatGPT is both a strength and a challenge. On one hand, it enables the model to generate a wide range of responses, making it versatile and creative. On the other hand, it can sometimes produce unexpected or less relevant outputs, which requires careful tuning and fine-tuning to ensure high-quality responses.
In the next section, we'll dive deeper into the inner workings of ChatGPT, exploring the Transformer architecture that powers it and how it models the sequence of words to generate coherent text. Stay tuned!
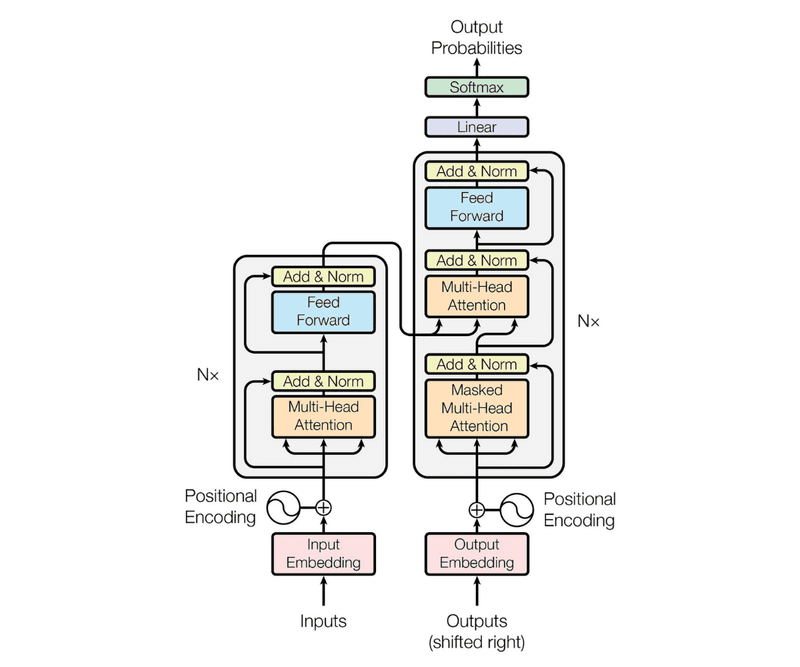
Under the Hood of ChatGPT
Neural Networks and Sequence Modeling
At the heart of ChatGPT lies a sophisticated neural network designed to model sequences of words and generate coherent text. To understand how ChatGPT works, it's essential to grasp the basics of neural networks and sequence modeling.
Neural Networks
Neural networks are computational models inspired by the human brain. They consist of layers of interconnected nodes (neurons) that process input data and learn patterns through training. Each connection between neurons has an associated weight, which is adjusted during training to minimize the error between the network's predictions and the actual outcomes.
In the context of language modeling, neural networks are used to predict the next word in a sequence based on the previous words. This involves learning the statistical properties of language and capturing the dependencies between words.
Sequence Modeling
Sequence modeling is a type of machine learning task where the goal is to predict the next element in a sequence based on the previous elements. In natural language processing (NLP), sequence modeling is crucial for tasks such as language translation, text generation, and speech recognition.
Traditional sequence modeling approaches, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory Networks (LSTMs), have been used to capture dependencies in sequences. However, these models have limitations, especially when it comes to handling long-range dependencies.
The Transformer Architecture
The Transformer architecture, introduced in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017, revolutionized sequence modeling by addressing the limitations of RNNs and LSTMs. The Transformer architecture relies on a mechanism called self-attention, which allows it to capture dependencies between words, regardless of their distance in the sequence.
Key Components of the Transformer
-
Self-Attention Mechanism:
- The self-attention mechanism enables the model to weigh the importance of different words in a sequence when making predictions. It computes a set of attention scores that determine how much focus each word should receive based on its relevance to the current word being processed.
- The self-attention mechanism involves three main steps:
- Query, Key, and Value Vectors: For each word in the sequence, the model generates three vectors: a query vector, a key vector, and a value vector. These vectors are obtained by multiplying the word's embedding with learned weight matrices.
- Attention Scores: The query vector of the current word is dot-multiplied with the key vectors of all words in the sequence to compute attention scores. These scores are then normalized using a softmax function to obtain attention weights.
- Weighted Sum: The attention weights are used to compute a weighted sum of the value vectors, resulting in a context vector that captures the relevant information from the entire sequence.
-
Multi-Head Attention:
- To capture different types of dependencies and relationships between words, the Transformer uses multiple self-attention heads. Each head operates independently and focuses on different aspects of the sequence. The outputs of all heads are concatenated and linearly transformed to produce the final output.
- Multi-head attention allows the model to attend to different parts of the sequence simultaneously, enhancing its ability to capture complex patterns.
-
Positional Encoding:
- Unlike RNNs and LSTMs, the Transformer does not inherently capture the order of words in a sequence. To address this, positional encoding is added to the word embeddings to provide information about the position of each word in the sequence.
- Positional encodings are typically sine and cosine functions of different frequencies, which are added to the word embeddings before they are fed into the self-attention mechanism.
-
Feed-Forward Neural Networks:
- After the self-attention mechanism, the output is passed through a feed-forward neural network (FFN) to introduce non-linearity and enable more complex transformations. The FFN consists of two linear layers with a ReLU activation function in between.
- The FFN operates independently on each position in the sequence, allowing the model to process each word's context separately.
-
Residual Connections and Layer Normalization:
- To facilitate training and improve gradient flow, the Transformer architecture employs residual connections and layer normalization. Residual connections add the input of a layer to its output, helping to preserve information and mitigate the vanishing gradient problem.
- Layer normalization normalizes the output of each layer to have zero mean and unit variance, stabilizing the training process and improving convergence.
The Transformer Block
A Transformer block consists of the following components:
-
Multi-Head Self-Attention:
- Computes attention scores and context vectors for each word in the sequence using multiple attention heads.
-
Add & Norm:
- Adds the input of the self-attention layer to its output (residual connection) and applies layer normalization.
-
Feed-Forward Neural Network:
- Applies a feed-forward neural network to the output of the self-attention layer.
-
Add & Norm:
- Adds the input of the feed-forward layer to its output (residual connection) and applies layer normalization.
The Transformer model is composed of multiple stacked Transformer blocks, allowing it to capture increasingly complex patterns and dependencies in the input sequence.
Building Your Own Transformer
While building a full-scale Transformer model like ChatGPT requires significant computational resources and expertise, you can create a simplified version to understand the core concepts. Here's a high-level overview of the steps involved:
-
Data Preparation:
- Collect and preprocess a dataset of text sequences. Tokenize the text into words or subwords and create input-output pairs for training.
-
Model Architecture:
- Define the Transformer architecture, including the number of layers, attention heads, and hidden dimensions. Implement the self-attention mechanism, multi-head attention, positional encoding, feed-forward neural networks, residual connections, and layer normalization.
-
Training:
- Train the Transformer model on the prepared dataset using a suitable optimization algorithm (e.g., Adam) and loss function (e.g., cross-entropy loss). Monitor the training process and adjust hyperparameters as needed.
-
Evaluation and Fine-Tuning:
- Evaluate the trained model on a validation set to assess its performance. Fine-tune the model on specific tasks or datasets to improve its accuracy and relevance.
By following these steps, you can gain hands-on experience with the Transformer architecture and appreciate the intricacies of sequence modeling and text generation.
In the next section, we'll dive into the practical aspects of building a Transformer-based language model, including data preparation, model implementation, and training. Stay tuned!

Building a Transformer-Based Language Model
In this section, we'll walk through the practical steps of building a Transformer-based language model. We'll cover setting up the environment, choosing a dataset, tokenization and encoding, and training a character-level language model. By the end of this section, you'll have a solid understanding of how to implement and train your own Transformer-based model.
Setting Up the Environment
Before we dive into the code, let's set up the environment. We'll be using Python and several libraries to build and train our model. Here's a list of the essential libraries you'll need:
- PyTorch: A popular deep learning library for building and training neural networks.
- NumPy: A library for numerical computations.
- Matplotlib: A plotting library for visualizing data (optional).
- tqdm: A library for displaying progress bars (optional).
You can install these libraries using pip:
pip install torch numpy matplotlib tqdmNext, let's create a new Python script or Jupyter notebook to implement our model. We'll start by importing the necessary libraries:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdmChoosing a Dataset
For this tutorial, we'll use the "Tiny Shakespeare" dataset, which is a concatenation of all of Shakespeare's works in a single text file. This dataset is small enough to train on a personal computer but still provides a rich source of text for our language model.
You can download the Tiny Shakespeare dataset from the following URL:
Save the dataset as input.txt in your working directory.
Tokenization and Encoding
Tokenization is the process of converting raw text into a sequence of tokens (e.g., characters or words). For this tutorial, we'll use character-level tokenization, where each character in the text is treated as a token.
First, let's load the dataset and inspect the first few characters:
# Load the dataset
with open('input.txt', 'r') as f:
text = f.read()
# Print the first 1000 characters
print(text[:1000])Next, we'll create a vocabulary of all unique characters in the dataset and map each character to a unique integer. This will allow us to encode the text as a sequence of integers.
# Create a vocabulary of unique characters
chars = sorted(list(set(text)))
vocab_size = len(chars)
print(f'Vocabulary size: {vocab_size}')
# Create mappings from characters to integers and vice versa
char_to_idx = {ch: i for i, ch in enumerate(chars)}
idx_to_char = {i: ch for i, ch in enumerate(chars)}
# Encode the entire text as a sequence of integers
encoded_text = np.array([char_to_idx[ch] for ch in text])
print(f'Encoded text: {encoded_text[:100]}')Training a Character-Level Language Model
Now that we have our dataset encoded as a sequence of integers, we can start building our Transformer-based language model. We'll define a simple Transformer architecture and train it to predict the next character in the sequence.
Model Architecture
We'll start by defining the Transformer architecture. Our model will consist of an embedding layer, several Transformer blocks, and a final linear layer to predict the next character.
class TransformerModel(nn.Module):
def __init__(self, vocab_size, embed_size, num_heads, num_layers, block_size, dropout=0.1):
super(TransformerModel, self).__init__()
self.embed_size = embed_size
self.block_size = block_size
# Embedding layer
self.token_embedding = nn.Embedding(vocab_size, embed_size)
self.position_embedding = nn.Embedding(block_size, embed_size)
# Transformer blocks
self.transformer_blocks = nn.ModuleList([
nn.TransformerEncoderLayer(embed_size, num_heads, dim_feedforward=embed_size * 4, dropout=dropout)
for _ in range(num_layers)
])
# Final linear layer
self.fc = nn.Linear(embed_size, vocab_size)
def forward(self, x):
# Get the batch size and sequence length
batch_size, seq_length = x.size()
# Create position indices
positions = torch.arange(0, seq_length, device=x.device).unsqueeze(0).expand(batch_size, seq_length)
# Embed tokens and positions
x = self.token_embedding(x) + self.position_embedding(positions)
# Apply Transformer blocks
for block in self.transformer_blocks:
x = block(x)
# Predict the next character
logits = self.fc(x)
return logitsTraining Loop
Next, we'll define the training loop. We'll use the cross-entropy loss function and the Adam optimizer to train our model. We'll also create batches of data and implement a function to generate text from the trained model.
def train_model(model, data, epochs, batch_size, block_size, learning_rate):
# Create the optimizer and loss function
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
# Training loop
for epoch in range(epochs):
model.train()
total_loss = 0
# Create batches of data
for i in range(0, len(data) - block_size, batch_size):
inputs = torch.tensor([data[j:j + block_size] for j in range(i, i + batch_size)], dtype=torch.long)
targets = torch.tensor([data[j + 1:j + block_size + 1] for j in range(i, i + batch_size)], dtype=torch.long)
# Move data to the device (GPU or CPU)
inputs, targets = inputs.to(device), targets.to(device)
# Zero the gradients
optimizer.zero_grad()
# Forward pass
logits = model(inputs)
# Compute the loss
loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
total_loss += loss.item()
# Backward pass and optimization
loss.backward()
optimizer.step()
# Print the average loss for the epoch
avg_loss = total_loss / (len(data) // batch_size)
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}')
def generate_text(model, start_text, length):
model.eval()
input_text = torch.tensor([char_to_idx[ch] for ch in start_text], dtype=torch.long).unsqueeze(0).to(device)
generated_text = start_text
for _ in range(length):
logits = model(input_text)
next_char_idx = torch.argmax(logits[0, -1]).item()
next_char = idx_to_char[next_char_idx]
generated_text += next_char
input_text = torch.cat([input_text, torch.tensor([[next_char_idx]], dtype=torch.long).to(device)], dim=1)
input_text = input_text[:, -block_size:]
return generated_textTraining the Model
Finally, we'll set the hyperparameters, create an instance of the model, and train it on the Tiny Shakespeare dataset.
# Hyperparameters
embed_size = 128
num_heads = 8
num_layers = 6
block_size = 128
dropout = 0.1
learning_rate = 0.001
epochs = 10
batch_size = 64
# Create the model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = TransformerModel(vocab_size, embed_size, num_heads, num_layers, block_size, dropout).to(device)
# Train the model
train_model(model, encoded_text, epochs, batch_size, block_size, learning_rate)
# Generate text
start_text = "To be, or not to be, that is the question:\n"
generated_text = generate_text(model, start_text, 500)
print(generated_text)By following these steps, you'll be able to build and train your own Transformer-based language model. This model will be capable of generating text in the style of Shakespeare, demonstrating the power and flexibility of the Transformer architecture.
In the next section, we'll explore more advanced techniques for fine-tuning and optimizing your language model, as well as how to scale it up for larger datasets and more complex tasks. Stay tuned!
Implementing a Simple Bigram Model
Before diving deeper into the complexities of the Transformer architecture, it's beneficial to start with a simpler model to grasp the basics of language modeling. In this section, we'll implement a simple bigram model, evaluate its performance, and generate text using the trained model.
Creating the Bigram Model
A bigram model is one of the simplest forms of language models. It predicts the next character in a sequence based solely on the current character. Despite its simplicity, it provides a good foundation for understanding more complex models.
Let's start by defining the bigram model. We'll use PyTorch to implement this model.
class BigramModel(nn.Module):
def __init__(self, vocab_size):
super(BigramModel, self).__init__()
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, vocab_size)
def forward(self, x):
# The input x is a tensor of shape (batch_size, seq_length)
# The embedding layer will transform it to (batch_size, seq_length, vocab_size)
logits = self.embedding(x)
return logitsIn this model, the nn.Embedding layer is used to map each character to a vector of probabilities over the vocabulary. The model directly predicts the next character based on the current character's embedding.
Evaluating the Model
To evaluate the performance of our bigram model, we'll use the cross-entropy loss function, which is suitable for classification tasks. We'll also define a training loop to optimize the model using the Adam optimizer.
def train_bigram_model(model, data, epochs, batch_size, block_size, learning_rate):
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for i in range(0, len(data) - block_size, batch_size):
inputs = torch.tensor([data[j:j + block_size] for j in range(i, i + batch_size)], dtype=torch.long)
targets = torch.tensor([data[j + 1:j + block_size + 1] for j in range(i, i + batch_size)], dtype=torch.long)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(inputs)
loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
total_loss += loss.item()
loss.backward()
optimizer.step()
avg_loss = total_loss / (len(data) // batch_size)
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}')Generating Text with the Bigram Model
Once the model is trained, we can use it to generate text. We'll start with a given character and repeatedly sample the next character based on the probabilities predicted by the model.
def generate_text_bigram(model, start_text, length):
model.eval()
input_text = torch.tensor([char_to_idx[ch] for ch in start_text], dtype=torch.long).unsqueeze(0).to(device)
generated_text = start_text
for _ in range(length):
logits = model(input_text)
next_char_idx = torch.argmax(logits[0, -1]).item()
next_char = idx_to_char[next_char_idx]
generated_text += next_char
input_text = torch.cat([input_text, torch.tensor([[next_char_idx]], dtype=torch.long).to(device)], dim=1)
input_text = input_text[:, -1:]
return generated_textTraining and Generating Text
Now, let's set the hyperparameters, create an instance of the bigram model, and train it on the Tiny Shakespeare dataset. After training, we'll generate some text to see how well the model performs.
# Hyperparameters
learning_rate = 0.01
epochs = 20
batch_size = 64
block_size = 1 # Bigram model only looks at the current character
# Create the bigram model
bigram_model = BigramModel(vocab_size).to(device)
# Train the bigram model
train_bigram_model(bigram_model, encoded_text, epochs, batch_size, block_size, learning_rate)
# Generate text with the bigram model
start_text = "T"
generated_text = generate_text_bigram(bigram_model, start_text, 500)
print(generated_text)By following these steps, you'll be able to implement a simple bigram model, train it on a dataset, and generate text. While the bigram model is limited in its ability to capture long-range dependencies, it serves as a useful introduction to language modeling and sets the stage for more advanced models like the Transformer.
In the next section, we'll delve into the intricacies of the Transformer architecture and explore how it overcomes the limitations of simpler models like the bigram model. Stay tuned!
Introducing the Transformer
The Transformer architecture, introduced in the seminal paper "Attention is All You Need" by Vaswani et al. in 2017, has revolutionized the field of natural language processing (NLP). Unlike traditional recurrent neural networks (RNNs) and long short-term memory networks (LSTMs), the Transformer relies entirely on self-attention mechanisms to capture dependencies between words in a sequence. This allows it to handle long-range dependencies more effectively and efficiently.
In this section, we'll delve into the core components of the Transformer architecture, including self-attention, multi-head attention, and feed-forward networks. We'll also implement these components step-by-step to build a deeper understanding of how they work.
Understanding Self-Attention
Self-attention is the cornerstone of the Transformer architecture. It enables the model to weigh the importance of different words in a sequence when making predictions. The self-attention mechanism involves three main steps:
-
Query, Key, and Value Vectors:
- For each word in the sequence, the model generates three vectors: a query vector, a key vector, and a value vector. These vectors are obtained by multiplying the word's embedding with learned weight matrices.
- The query vector represents what the current word is looking for in the context of the sequence.
- The key vector represents the content of each word in the sequence.
- The value vector represents the information that will be aggregated based on the attention scores.
-
Attention Scores:
- The query vector of the current word is dot-multiplied with the key vectors of all words in the sequence to compute attention scores. These scores determine how much focus each word should receive based on its relevance to the current word.
- The attention scores are then normalized using a softmax function to obtain attention weights.
-
Weighted Sum:
- The attention weights are used to compute a weighted sum of the value vectors, resulting in a context vector that captures the relevant information from the entire sequence.
Mathematically, the self-attention mechanism can be represented as follows:
Where:
- is the matrix of query vectors.
- is the matrix of key vectors.
- is the matrix of value vectors.
- is the dimensionality of the key vectors.
Implementing Self-Attention
Let's implement the self-attention mechanism in PyTorch. We'll start by defining a class for self-attention and then integrate it into our Transformer model.
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
# Split the embedding into self.heads different pieces
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
# Calculate the dot product attention scores
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return outMulti-Head Attention
Multi-head attention extends the self-attention mechanism by allowing the model to focus on different parts of the sequence simultaneously. Instead of using a single set of query, key, and value vectors, multi-head attention uses multiple sets (heads) and concatenates their outputs.
This allows the model to capture different types of dependencies and relationships between words, enhancing its ability to understand complex patterns in the text.
Let's implement multi-head attention by integrating multiple self-attention heads into our model.
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.self_attention = SelfAttention(embed_size, heads)
def forward(self, values, keys, query, mask):
return self.self_attention(values, keys, query, mask)Feed-Forward Networks
After the self-attention mechanism, the Transformer applies a feed-forward neural network (FFN) to each position in the sequence independently. The FFN consists of two linear layers with a ReLU activation function in between.
The feed-forward network introduces non-linearity and enables more complex transformations, allowing the model to capture intricate patterns in the text.
Let's implement the feed-forward network in PyTorch.
class FeedForward(nn.Module):
def __init__(self, embed_size, forward_expansion):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(embed_size, forward_expansion * embed_size)
self.fc2 = nn.Linear(forward_expansion * embed_size, embed_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return xIntegrating Components into the Transformer Block
Now that we have implemented self-attention, multi-head attention, and feed-forward networks, let's integrate them into a Transformer block. Each block will consist of multi-head attention followed by a feed-forward network, with residual connections and layer normalization applied at each step.
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = FeedForward(embed_size, forward_expansion)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return outBuilding the Complete Transformer Model
Finally, let's build the complete Transformer model by stacking multiple Transformer blocks. We'll also include an embedding layer for the input tokens and positional encodings to provide information about the position of each word in the sequence.
class Transformer(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
):
super(Transformer, self).__init__()
self.embed_size = embed_size
self.word_embedding = nn.Embedding(vocab_size, embed_size)
self.position_embedding = nn.Embedding(max_length, embed_size)
self.layers = nn.ModuleList(
[
TransformerBlock(embed_size, heads, forward_expansion, dropout)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(x.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
out = self.fc_out(out)
return outTraining the Transformer Model
With the complete Transformer model defined, we can now train it on our dataset. We'll use the same training loop and text generation functions as before, but with the Transformer model.
# Hyperparameters
embed_size = 256
num_layers = 6
heads = 8
forward_expansion = 4
dropout = 0.1
max_length = 100
learning_rate = 0.001
epochs = 10
batch_size = 64
# Create the Transformer model
model = Transformer(
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
).to(device)
# Train the Transformer model
train_model(model, encoded_text, epochs, batch_size, max_length, learning_rate)
# Generate text with the Transformer model
start_text = "To be, or not to be, that is the question:\n"
generated_text = generate_text(model, start_text, 500)
print(generated_text)By following these steps, you'll be able to implement and train a Transformer-based language model. This model will be capable of generating coherent and contextually relevant text, demonstrating the power and flexibility of the Transformer architecture.
In the next section, we'll explore more advanced techniques for fine-tuning and optimizing your language model, as well as how to scale it up for larger datasets and more complex tasks. Stay tuned!
Building a Complete Transformer
In this section, we'll bring together all the components we've discussed so far to build a complete Transformer model. We'll focus on combining attention and feed-forward layers, adding positional encoding, and incorporating layer normalization and residual connections. By the end of this section, you'll have a fully functional Transformer model capable of handling complex language modeling tasks.
Combining Attention and Feed-Forward Layers
The core of the Transformer model consists of alternating layers of multi-head self-attention and feed-forward neural networks. Each Transformer block is designed to capture dependencies between words and perform complex transformations on the input data.
Let's start by defining the Transformer block, which combines multi-head self-attention and feed-forward layers:
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = FeedForward(embed_size, forward_expansion)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return outIn this implementation:
MultiHeadAttentioncomputes the attention scores and context vectors.LayerNormnormalizes the output of the attention and feed-forward layers.Dropoutis applied to prevent overfitting.- Residual connections (
+ queryand+ x) ensure that the model can learn effectively even with deep architectures.
Adding Positional Encoding
Transformers do not inherently capture the order of words in a sequence. To address this, we add positional encodings to the input embeddings. Positional encodings provide information about the position of each word in the sequence, enabling the model to understand the order of words.
We'll define a function to generate positional encodings and integrate it into our Transformer model:
class PositionalEncoding(nn.Module):
def __init__(self, embed_size, max_length):
super(PositionalEncoding, self).__init__()
self.embed_size = embed_size
# Create a matrix of shape (max_length, embed_size)
pe = torch.zeros(max_length, embed_size)
position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return xLayer Normalization and Residual Connections
Layer normalization and residual connections are crucial for stabilizing the training process and improving gradient flow in deep networks. Residual connections allow gradients to flow directly through the network, while layer normalization ensures that the outputs of each layer have a consistent distribution.
We've already incorporated layer normalization and residual connections in our TransformerBlock class. Now, let's integrate all the components into the complete Transformer model:
class Transformer(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
):
super(Transformer, self).__init__()
self.embed_size = embed_size
self.word_embedding = nn.Embedding(vocab_size, embed_size)
self.position_embedding = PositionalEncoding(embed_size, max_length)
self.layers = nn.ModuleList(
[
TransformerBlock(embed_size, heads, forward_expansion, dropout)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(x.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
out = self.fc_out(out)
return outTraining the Complete Transformer Model
With the complete Transformer model defined, we can now train it on our dataset. We'll use the same training loop and text generation functions as before, but with the Transformer model.
# Hyperparameters
embed_size = 256
num_layers = 6
heads = 8
forward_expansion = 4
dropout = 0.1
max_length = 100
learning_rate = 0.001
epochs = 10
batch_size = 64
# Create the Transformer model
model = Transformer(
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
).to(device)
# Train the Transformer model
train_model(model, encoded_text, epochs, batch_size, max_length, learning_rate)
# Generate text with the Transformer model
start_text = "To be, or not to be, that is the question:\n"
generated_text = generate_text(model, start_text, 500)
print(generated_text)By following these steps, you'll have a fully functional Transformer model capable of handling complex language modeling tasks. This model will be able to generate coherent and contextually relevant text, demonstrating the power and flexibility of the Transformer architecture.
In the next section, we'll explore more advanced techniques for fine-tuning and optimizing your language model, as well as how to scale it up for larger datasets and more complex tasks. Stay tuned!
Scaling Up the Model
As we move towards building more powerful and capable language models, it's essential to understand how to scale up the model effectively. This involves increasing the model size and complexity, applying regularization techniques to prevent overfitting, and training on larger datasets to improve generalization. In this section, we'll explore these aspects in detail.
Increasing Model Size and Complexity
Increasing the size and complexity of a Transformer model can significantly enhance its performance and ability to capture intricate patterns in the data. Here are some key strategies for scaling up the model:
-
Increasing the Number of Layers:
- Adding more Transformer blocks (layers) allows the model to learn more complex representations. Each additional layer enables the model to capture higher-level abstractions and dependencies in the text.
-
Increasing the Embedding Size:
- A larger embedding size provides more capacity for the model to represent the input tokens. This can lead to better performance, especially for tasks that require understanding subtle nuances in the text.
-
Increasing the Number of Attention Heads:
- Using more attention heads in the multi-head attention mechanism allows the model to focus on different parts of the sequence simultaneously. This can improve the model's ability to capture diverse patterns and relationships between words.
-
Increasing the Feed-Forward Network Size:
- Expanding the size of the feed-forward network within each Transformer block allows for more complex transformations of the input data. This can enhance the model's ability to process and generate text.
Let's update our Transformer model to incorporate these changes:
# Updated Hyperparameters for a Larger Model
embed_size = 512
num_layers = 12
heads = 16
forward_expansion = 4
dropout = 0.1
max_length = 512
learning_rate = 0.0001
epochs = 20
batch_size = 128
# Create the larger Transformer model
model = Transformer(
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
).to(device)
# Train the larger Transformer model
train_model(model, encoded_text, epochs, batch_size, max_length, learning_rate)
# Generate text with the larger Transformer model
start_text = "To be, or not to be, that is the question:\n"
generated_text = generate_text(model, start_text, 500)
print(generated_text)Regularization Techniques
As we scale up the model, the risk of overfitting increases. Regularization techniques are essential to prevent overfitting and ensure that the model generalizes well to unseen data. Here are some common regularization techniques:
-
Dropout:
- Dropout is a regularization technique where randomly selected neurons are ignored (dropped out) during training. This prevents the model from becoming too reliant on specific neurons and encourages it to learn more robust features.
- Dropout is already integrated into our Transformer model. You can adjust the dropout rate to control the level of regularization.
-
Weight Decay (L2 Regularization):
- Weight decay adds a penalty to the loss function based on the magnitude of the model's weights. This discourages the model from learning excessively large weights, which can lead to overfitting.
- You can apply weight decay by setting the
weight_decayparameter in the optimizer.
-
Gradient Clipping:
- Gradient clipping limits the magnitude of gradients during training. This prevents the model from making large updates to the weights, which can destabilize the training process and lead to overfitting.
- You can implement gradient clipping using the
torch.nn.utils.clip_grad_norm_function.
Let's update our training loop to incorporate weight decay and gradient clipping:
def train_model_with_regularization(model, data, epochs, batch_size, block_size, learning_rate, weight_decay, clip_value):
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for i in range(0, len(data) - block_size, batch_size):
inputs = torch.tensor([data[j:j + block_size] for j in range(i, i + batch_size)], dtype=torch.long)
targets = torch.tensor([data[j + 1:j + block_size + 1] for j in range(i, i + batch_size)], dtype=torch.long)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(inputs)
loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
total_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_value)
optimizer.step()
avg_loss = total_loss / (len(data) // batch_size)
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}')Training on Larger Datasets
Training on larger datasets is crucial for improving the generalization and performance of the model. Larger datasets provide more diverse examples, enabling the model to learn a broader range of patterns and relationships in the text.
Here are some strategies for training on larger datasets:
-
Data Augmentation:
- Data augmentation techniques, such as synonym replacement, random insertion, and back-translation, can increase the size and diversity of the training data. This helps the model generalize better to unseen data.
-
Distributed Training:
- Distributed training involves training the model on multiple GPUs or machines simultaneously. This allows for faster training on large datasets and enables the use of larger models.
- PyTorch provides tools for distributed training, such as
torch.distributedandtorch.nn.DataParallel.
-
Pre-training and Fine-tuning:
- Pre-training the model on a large, diverse corpus of text (e.g., Wikipedia, Common Crawl) allows it to learn general language patterns. The model can then be fine-tuned on a smaller, task-specific dataset to improve performance on the target task.
- This approach is commonly used in state-of-the-art models like GPT-3 and BERT.
Let's update our training script to handle larger datasets and incorporate distributed training:
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
def train_model_distributed(model, data, epochs, batch_size, block_size, learning_rate, weight_decay, clip_value):
dist.init_process_group(backend='nccl')
model = DDP(model)
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for i in range(0, len(data) - block_size, batch_size):
inputs = torch.tensor([data[j:j + block_size] for j in range(i, i + batch_size)], dtype=torch.long)
targets = torch.tensor([data[j + 1:j + block_size + 1] for j in range(i, i + batch_size)], dtype=torch.long)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(inputs)
loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
total_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_value)
optimizer.step()
avg_loss = total_loss / (len(data) // batch_size)
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}')
dist.destroy_process_group()By following these strategies, you can scale up your Transformer model to handle larger datasets and more complex tasks. This will enable you to build more powerful and capable language models that can generate high-quality text and perform a wide range of NLP tasks.
In the next section, we'll explore advanced techniques for fine-tuning and optimizing your language model, as well as how to deploy it for real-world applications. Stay tuned!
Fine-Tuning and Practical Applications
Fine-Tuning for Specific Tasks
While pre-trained language models like ChatGPT are powerful, they often need to be fine-tuned for specific tasks to achieve optimal performance. Fine-tuning involves training the pre-trained model on a smaller, task-specific dataset to adapt it to the nuances of the target task. This process leverages the general language understanding acquired during pre-training and refines it for specialized applications.
Steps for Fine-Tuning
-
Dataset Preparation:
- Collect and preprocess a dataset that is relevant to the specific task. This dataset should include input-output pairs that reflect the desired behavior of the model.
- For example, if you're fine-tuning a model for sentiment analysis, the dataset should consist of text samples labeled with their corresponding sentiment (positive, negative, neutral).
-
Model Initialization:
- Load the pre-trained model and initialize it with the pre-trained weights. This provides a strong starting point for fine-tuning.
-
Task-Specific Modifications:
- Depending on the task, you may need to modify the model architecture slightly. For instance, you might add a classification head for tasks like sentiment analysis or a sequence-to-sequence head for translation tasks.
-
Training:
- Train the model on the task-specific dataset using a suitable optimization algorithm and loss function. Fine-tuning typically requires fewer epochs than pre-training since the model is already well-initialized.
- Monitor the training process and adjust hyperparameters as needed to achieve the best performance.
-
Evaluation:
- Evaluate the fine-tuned model on a validation set to assess its performance. Fine-tuning should improve the model's accuracy and relevance for the specific task.
Example: Fine-Tuning for Sentiment Analysis
Let's walk through an example of fine-tuning a pre-trained Transformer model for sentiment analysis. We'll use the IMDb movie reviews dataset, which contains text samples labeled with their sentiment (positive or negative).
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification
# Load the IMDb dataset
from datasets import load_dataset
dataset = load_dataset("imdb")
# Preprocess the dataset
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=512)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# Split the dataset into train and test sets
train_dataset = encoded_dataset["train"]
test_dataset = encoded_dataset["test"]
# Load the pre-trained GPT-2 model with a classification head
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=2)
# Define the training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Define the trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# Fine-tune the model
trainer.train()
# Evaluate the model
results = trainer.evaluate()
print(results)In this example:
- We load the IMDb dataset and preprocess it using the GPT-2 tokenizer.
- We initialize a pre-trained GPT-2 model with a classification head for sentiment analysis.
- We define the training arguments and create a
Trainerobject to handle the fine-tuning process. - We fine-tune the model on the IMDb dataset and evaluate its performance.
Practical Applications of ChatGPT
ChatGPT has a wide range of practical applications across various domains. Its ability to generate coherent and contextually relevant text makes it a valuable tool for numerous tasks. Here are some notable applications:
-
Customer Support:
- ChatGPT can be integrated into customer support systems to provide instant responses to customer queries. It can handle common questions, troubleshoot issues, and escalate complex cases to human agents.
- Example: A chatbot on an e-commerce website that assists customers with order tracking, returns, and product inquiries.
-
Content Creation:
- ChatGPT can assist content creators by generating ideas, drafting articles, and providing suggestions for improving text. It can also be used to create social media posts, blog articles, and marketing copy.
- Example: A content generation tool that helps marketers create engaging social media posts and blog articles.
-
Language Translation:
- ChatGPT can be fine-tuned for language translation tasks, enabling it to translate text between different languages. This can be useful for businesses operating in multiple regions and for individuals seeking to communicate across language barriers.
- Example: A translation service that provides real-time translations for documents, emails, and chat messages.
-
Virtual Assistants:
- ChatGPT can power virtual assistants that help users with various tasks, such as setting reminders, managing schedules, and providing information. Virtual assistants can be integrated into smartphones, smart speakers, and other devices.
- Example: A virtual assistant that helps users manage their daily tasks, set reminders, and answer questions about various topics.
-
Educational Tools:
- ChatGPT can be used to create educational tools that provide personalized learning experiences. It can generate explanations, answer questions, and provide feedback on assignments.
- Example: An educational platform that uses ChatGPT to provide personalized tutoring and answer students' questions on various subjects.
-
Creative Writing:
- ChatGPT can assist writers by generating creative content, such as stories, poems, and scripts. It can provide inspiration, suggest plot twists, and help overcome writer's block.
- Example: A writing assistant that helps authors brainstorm ideas, generate storylines, and draft creative content.
-
Healthcare:
- ChatGPT can be used in healthcare applications to provide information about medical conditions, suggest lifestyle changes, and assist with appointment scheduling. It can also be used to triage patients and provide preliminary diagnoses.
- Example: A healthcare chatbot that provides information about symptoms, suggests possible conditions, and helps users schedule appointments with healthcare providers.
-
Gaming:
- ChatGPT can enhance gaming experiences by generating dynamic dialogues, creating immersive storylines, and providing in-game assistance. It can also be used to create non-player characters (NPCs) with realistic interactions.
- Example: A role-playing game that uses ChatGPT to generate dynamic dialogues and create immersive storylines for players.
-
Legal Assistance:
- ChatGPT can assist with legal research, document drafting, and providing information about legal procedures. It can help users understand legal terms, draft contracts, and prepare for legal proceedings.
- Example: A legal assistant tool that helps users draft contracts, understand legal terms, and prepare for court cases.
-
Personalized Recommendations:
- ChatGPT can provide personalized recommendations for products, services, and content based on user preferences and behavior. It can enhance user experiences by suggesting relevant items and content.
- Example: A recommendation engine that suggests books, movies, and products based on user preferences and browsing history.
These practical applications demonstrate the versatility and potential of ChatGPT in various domains. By fine-tuning the model for specific tasks and integrating it into different systems, businesses and individuals can leverage its capabilities to enhance productivity, improve user experiences, and drive innovation.
In the next section, we'll explore advanced techniques for optimizing and deploying your language model, as well as how to ensure ethical and responsible use of AI technologies. Stay tuned!

Conclusion
Summary of Key Points
In this comprehensive guide, we delved into the intricacies of ChatGPT and the Transformer architecture, exploring how these advanced models are built, trained, and fine-tuned. Here are the key points we covered:
-
Introduction to ChatGPT:
- ChatGPT is a state-of-the-art language model developed by OpenAI, leveraging the Transformer architecture to generate human-like text.
- It can handle a wide range of text-based tasks, from creative writing to technical explanations.
-
Basics of Language Models:
- Language models predict the next word or sequence of words based on the given context.
- Different types of language models include n-gram models, RNNs, LSTMs, and Transformers.
-
Under the Hood of ChatGPT:
- The Transformer architecture, introduced in the "Attention is All You Need" paper, revolutionized NLP by using self-attention mechanisms.
- Key components of the Transformer include self-attention, multi-head attention, positional encoding, feed-forward networks, residual connections, and layer normalization.
-
Building a Transformer-Based Language Model:
- We implemented a simple bigram model to understand the basics of language modeling.
- We then built a complete Transformer model, combining attention and feed-forward layers, adding positional encoding, and incorporating layer normalization and residual connections.
-
Scaling Up the Model:
- We explored strategies for increasing the model size and complexity, applying regularization techniques, and training on larger datasets.
- Techniques like dropout, weight decay, gradient clipping, and distributed training help prevent overfitting and improve model performance.
-
Fine-Tuning and Practical Applications:
- Fine-tuning involves training a pre-trained model on a task-specific dataset to adapt it to the target task.
- ChatGPT has a wide range of practical applications, including customer support, content creation, language translation, virtual assistants, educational tools, creative writing, healthcare, gaming, legal assistance, and personalized recommendations.
Future Directions and Advanced Topics
As we look to the future, there are several exciting directions and advanced topics in the field of language modeling and AI that are worth exploring:
-
Larger and More Powerful Models:
- The trend towards larger models, such as GPT-3 and beyond, continues to push the boundaries of what language models can achieve. These models require significant computational resources but offer unprecedented capabilities in understanding and generating text.
-
Multimodal Models:
- Integrating text with other modalities, such as images, audio, and video, can create more versatile and powerful AI systems. Multimodal models can understand and generate content across different types of data, enabling applications like image captioning, video summarization, and audio transcription.
-
Few-Shot and Zero-Shot Learning:
- Few-shot and zero-shot learning techniques aim to enable models to perform tasks with minimal or no task-specific training data. This can significantly reduce the need for large labeled datasets and make AI more accessible for various applications.
-
Ethical and Responsible AI:
- Ensuring the ethical and responsible use of AI technologies is crucial. This includes addressing issues like bias, fairness, transparency, and accountability. Developing guidelines and best practices for ethical AI deployment is an ongoing area of research and discussion.
-
Efficient Training and Inference:
- Research into more efficient training and inference techniques aims to reduce the computational and energy costs associated with large language models. Techniques like model pruning, quantization, and knowledge distillation can help make AI more sustainable and accessible.
-
Personalization and Adaptability:
- Personalizing language models to individual users can enhance user experiences by providing more relevant and tailored responses. Adaptive models that can learn and evolve based on user interactions hold great promise for creating more intelligent and responsive systems.
-
Interdisciplinary Applications:
- The integration of language models with other fields, such as healthcare, education, finance, and law, can drive innovation and create new opportunities. Collaborative efforts between AI researchers and domain experts can lead to the development of specialized AI solutions for various industries.
-
Open Research and Collaboration:
- Open research and collaboration within the AI community are essential for advancing the field. Sharing datasets, models, and research findings can accelerate progress and ensure that the benefits of AI are widely distributed.
By staying informed about these future directions and advanced topics, researchers, developers, and practitioners can continue to push the boundaries of what is possible with language models and AI. The journey of exploring and harnessing the power of AI is ongoing, and the potential for innovation and positive impact is immense.
Thank you for following along with this guide. We hope it has provided valuable insights into the world of ChatGPT and the Transformer architecture. Go forth and transform the future with AI!

Appendix
Code Examples
In this section, we'll provide some additional code examples to help you get started with building and fine-tuning your own Transformer-based language models. These examples include setting up the environment, implementing the Transformer architecture, and training the model on a dataset.
Setting Up the Environment
First, let's set up the environment by installing the necessary libraries:
pip install torch numpy matplotlib tqdm transformers datasetsNext, create a new Python script or Jupyter notebook and import the required libraries:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
from tqdm import tqdm
from transformers import GPT2Tokenizer, GPT2ForSequenceClassification, TrainingArguments, Trainer
from datasets import load_datasetImplementing the Transformer Architecture
Here's a complete implementation of the Transformer architecture, including self-attention, multi-head attention, feed-forward networks, and positional encoding:
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
assert (
self.head_dim * heads == embed_size
), "Embedding size needs to be divisible by heads"
self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)
self.fc_out = nn.Linear(heads * self.head_dim, embed_size)
def forward(self, values, keys, query, mask):
N = query.shape[0]
value_len, key_len, query_len = values.shape[1], keys.shape[1], query.shape[1]
values = values.reshape(N, value_len, self.heads, self.head_dim)
keys = keys.reshape(N, key_len, self.heads, self.head_dim)
queries = query.reshape(N, query_len, self.heads, self.head_dim)
values = self.values(values)
keys = self.keys(keys)
queries = self.queries(queries)
energy = torch.einsum("nqhd,nkhd->nhqk", [queries, keys])
if mask is not None:
energy = energy.masked_fill(mask == 0, float("-1e20"))
attention = torch.softmax(energy / (self.embed_size ** (1 / 2)), dim=3)
out = torch.einsum("nhql,nlhd->nqhd", [attention, values]).reshape(
N, query_len, self.heads * self.head_dim
)
out = self.fc_out(out)
return out
class MultiHeadAttention(nn.Module):
def __init__(self, embed_size, heads):
super(MultiHeadAttention, self).__init__()
self.self_attention = SelfAttention(embed_size, heads)
def forward(self, values, keys, query, mask):
return self.self_attention(values, keys, query, mask)
class FeedForward(nn.Module):
def __init__(self, embed_size, forward_expansion):
super(FeedForward, self).__init__()
self.fc1 = nn.Linear(embed_size, forward_expansion * embed_size)
self.fc2 = nn.Linear(forward_expansion * embed_size, embed_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
class TransformerBlock(nn.Module):
def __init__(self, embed_size, heads, forward_expansion, dropout):
super(TransformerBlock, self).__init__()
self.attention = MultiHeadAttention(embed_size, heads)
self.norm1 = nn.LayerNorm(embed_size)
self.norm2 = nn.LayerNorm(embed_size)
self.feed_forward = FeedForward(embed_size, forward_expansion)
self.dropout = nn.Dropout(dropout)
def forward(self, value, key, query, mask):
attention = self.attention(value, key, query, mask)
x = self.dropout(self.norm1(attention + query))
forward = self.feed_forward(x)
out = self.dropout(self.norm2(forward + x))
return out
class PositionalEncoding(nn.Module):
def __init__(self, embed_size, max_length):
super(PositionalEncoding, self).__init__()
self.embed_size = embed_size
pe = torch.zeros(max_length, embed_size)
position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, embed_size, 2).float() * (-math.log(10000.0) / embed_size))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[:x.size(0), :]
return x
class Transformer(nn.Module):
def __init__(
self,
embed_size,
num_layers,
heads,
forward_expansion,
vocab_size,
max_length,
dropout,
):
super(Transformer, self).__init__()
self.embed_size = embed_size
self.word_embedding = nn.Embedding(vocab_size, embed_size)
self.position_embedding = PositionalEncoding(embed_size, max_length)
self.layers = nn.ModuleList(
[
TransformerBlock(embed_size, heads, forward_expansion, dropout)
for _ in range(num_layers)
]
)
self.fc_out = nn.Linear(embed_size, vocab_size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
N, seq_length = x.shape
positions = torch.arange(0, seq_length).expand(N, seq_length).to(x.device)
out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))
for layer in self.layers:
out = layer(out, out, out, mask)
out = self.fc_out(out)
return outTraining the Transformer Model
Here's the training loop for the Transformer model, including regularization techniques like weight decay and gradient clipping:
def train_model_with_regularization(model, data, epochs, batch_size, block_size, learning_rate, weight_decay, clip_value):
optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
for epoch in range(epochs):
model.train()
total_loss = 0
for i in range(0, len(data) - block_size, batch_size):
inputs = torch.tensor([data[j:j + block_size] for j in range(i, i + batch_size)], dtype=torch.long)
targets = torch.tensor([data[j + 1:j + block_size + 1] for j in range(i, i + batch_size)], dtype=torch.long)
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
logits = model(inputs)
loss = criterion(logits.view(-1, vocab_size), targets.view(-1))
total_loss += loss.item()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), clip_value)
optimizer.step()
avg_loss = total_loss / (len(data) // batch_size)
print(f'Epoch {epoch + 1}/{epochs}, Loss: {avg_loss:.4f}')Fine-Tuning for Specific Tasks
Here's an example of fine-tuning a pre-trained GPT-2 model for sentiment analysis using the IMDb dataset:
# Load the IMDb dataset
dataset = load_dataset("imdb")
# Preprocess the dataset
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding="max_length", max_length=512)
encoded_dataset = dataset.map(preprocess_function, batched=True)
# Split the dataset into train and test sets
train_dataset = encoded_dataset["train"]
test_dataset = encoded_dataset["test"]
# Load the pre-trained GPT-2 model with a classification head
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=2)
# Define the training arguments
training_args = TrainingArguments(
output_dir="./results",
evaluation_strategy="epoch",
learning_rate=2e-5,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=3,
weight_decay=0.01,
)
# Define the trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=test_dataset,
)
# Fine-tune the model
trainer.train()
# Evaluate the model
results = trainer.evaluate()
print(results)Additional Resources
To further your understanding and skills in building and fine-tuning Transformer-based language models, here are some additional resources:
-
Research Papers:
- "Attention is All You Need" by Vaswani et al. (2017): The seminal paper introducing the Transformer architecture.
- "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding" by Devlin et al. (2018): A paper on BERT, a widely used Transformer-based model for various NLP tasks.
- "Language Models are Few-Shot Learners" by Brown et al. (2020): The paper introducing GPT-3, a large-scale Transformer model.
-
Books:
- "Deep Learning" by Ian Goodfellow, Yoshua Bengio, and Aaron Courville: A comprehensive textbook on deep learning, covering fundamental concepts and advanced topics.
- "Natural Language Processing with PyTorch" by Delip Rao and Brian McMahan: A practical guide to building NLP models using PyTorch.
-
Online Courses:
- "Deep Learning Specialization" by Andrew Ng on Coursera: A series of courses covering deep learning fundamentals and applications.
- "Natural Language Processing with Deep Learning" by Stanford University (CS224N): A course on NLP with a focus on deep learning techniques, including Transformers.
-
Tutorials and Blogs:
- The official PyTorch tutorials: https://pytorch.org/tutorials/
- The Hugging Face blog: https://huggingface.co/blog/
- The OpenAI blog: https://openai.com/blog/
-
Libraries and Tools:
- PyTorch: https://pytorch.org/
- Hugging Face Transformers: https://huggingface.co/transformers/
- TensorFlow: https://www.tensorflow.org/
By exploring these resources, you'll gain a deeper understanding of Transformer-based language models and their applications. Happy learning and building!


